Exadata Smart Flash Log: Eliminating Redo Log Bottlenecks in Oracle Exadata
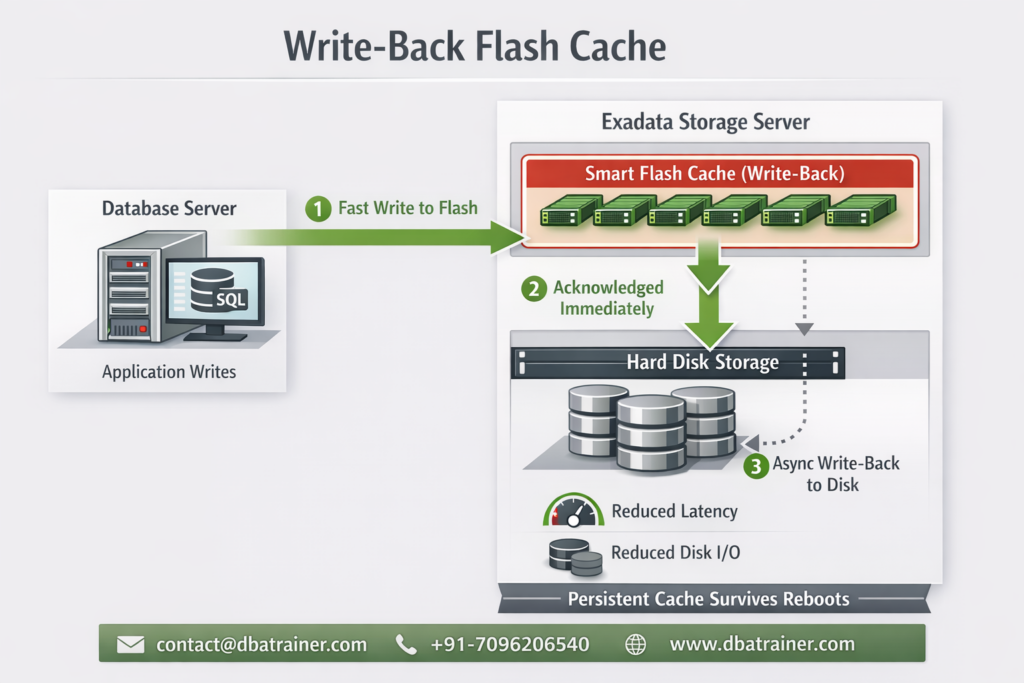
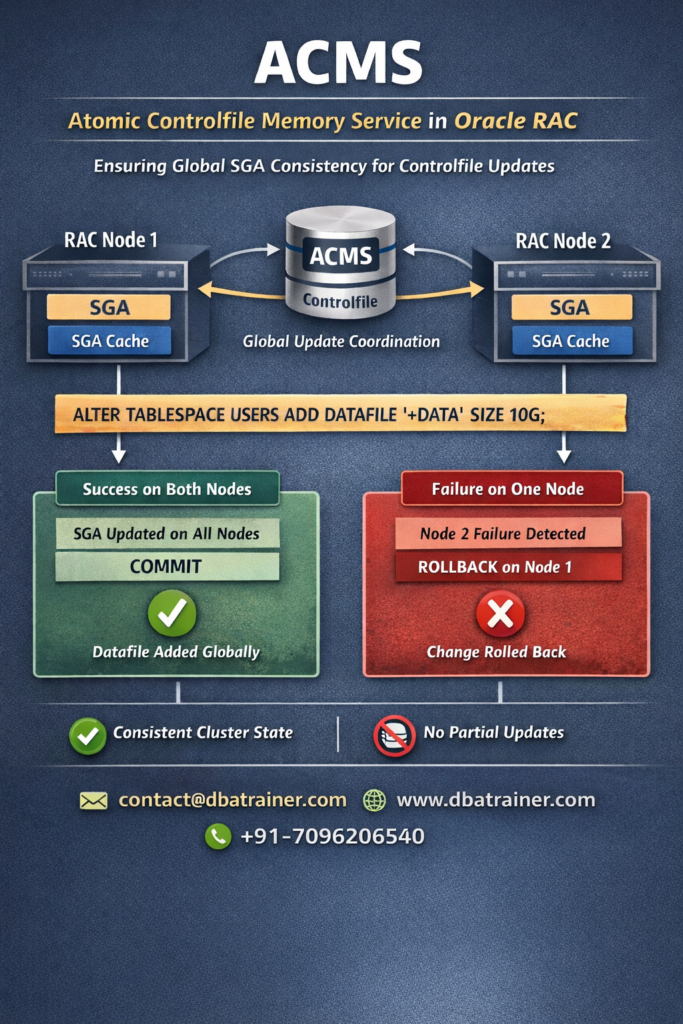
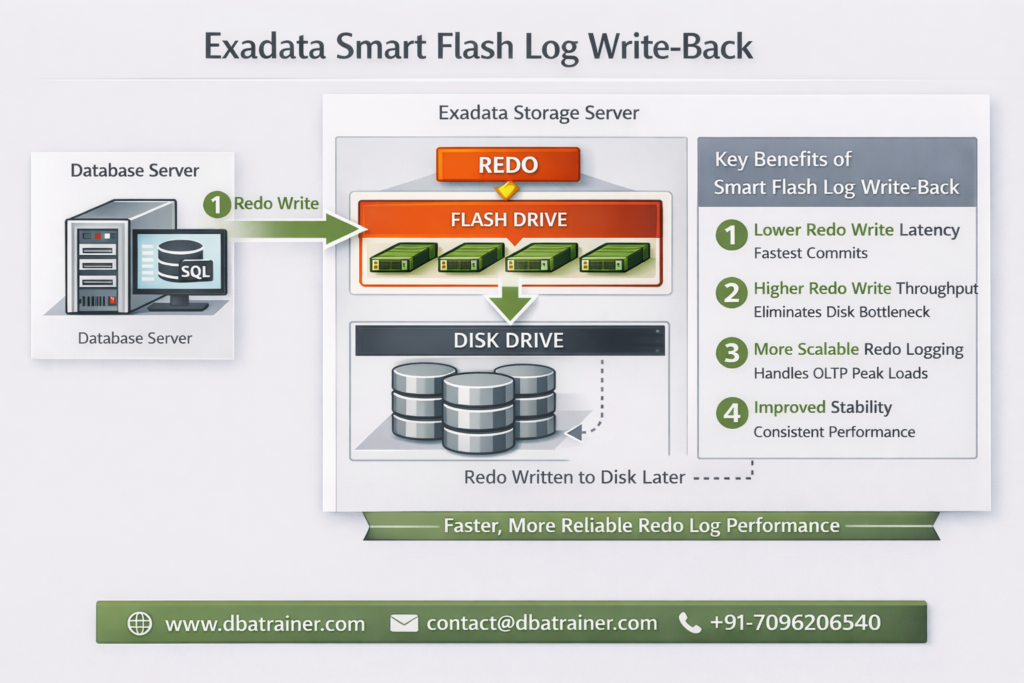
Exadata Smart Flash Log is designed to eliminate redo logging bottlenecks by accelerating performance-critical redo write operations in Oracle Exadata environments. In high-performance OLTP systems, transaction commit time is directly dependent on redo log write latency. Even small spikes in redo write latency can significantly impact response times and overall database throughput. What is Exadata Smart Flash Log? Exadata Smart Flash Log is a feature of Oracle Exadata that improves transaction response times by reducing redo log write latency using flash storage. Redo writes are extremely latency-sensitive because: Even though disk controllers use battery-backed DRAM cache, redo writes can still experience latency spikes when: Even a few slow redo writes can create noticeable performance degradation. How Exadata Smart Flash Log Works (Pre-20.1 Behavior) Before Oracle Exadata System Software 20.1, Exadata Smart Flash Log works as follows: Result: However, because redo must eventually persist to disk, overall logging throughput remained constrained by disk bandwidth. Smart Flash Log Write-Back (Introduced in 20.1) Starting with Oracle Exadata System Software 20.1, a major enhancement was introduced: Smart Flash Log Write-Back Instead of writing redo simultaneously to disk and flash, redo is written to: This removes disk as a bottleneck for redo logging. Benefits of Smart Flash Log Write-Back: This enhancement is particularly beneficial for: Why Exadata Smart Flash Log Is Important 1️⃣ Reduces log file sync Waits Commit response time improves immediately. 2️⃣ Eliminates Latency Spikes Parallel media writes prevent single-device delays from affecting commits. 3️⃣ Increases Database Throughput Higher redo throughput allows more transactions per second. 4️⃣ Improves Stability Under Load Performance remains consistent during peak I/O activity. Exadata Smart Flash Log vs Write-Back Flash Cache Feature Exadata Smart Flash Log Write-Back Flash Cache Applies To Redo logs Data files Improves Commit latency Data block write latency Wait Event Reduced log file sync db file parallel write Write Pattern Sequential Random 20.1 Enhancement Write-Back mode Already supported Use Case High commit OLTP Write-intensive workloads These features are complementary — not replacements. When Should You Investigate Exadata Smart Flash Log? Look at this feature if you observe: If redo is your bottleneck, Exadata Smart Flash Log is the solution. Final Thoughts Exadata Smart Flash Log is one of the most impactful performance optimizations available in Oracle Exadata for transaction-heavy environments. By reducing redo latency and eliminating logging bottlenecks, it: With the introduction of Smart Flash Log Write-Back in Exadata System Software 20.1, redo logging can now fully leverage flash performance — removing traditional disk limitations.
Exadata Smart Flash Log: Eliminating Redo Log Bottlenecks in Oracle Exadata Read More »